A broken link checker for Umbraco 7
Diplo Link Checker is a dashboard add-on for Umbraco 7 that allows an editor to easily check their site for broken or problematic links.
I've been a great fan of the Umbraco Content Management System for many years. It's powerful, flexible, open source and has a great community associated with it. One of its many great features is that it allows developers to contribute packages that extend or enhance Umbraco's functionality. Best of all, thanks to the ethos of open source, the vast majority of these packages are available to download free of charge. I have benefited greatly from some of the great packages so I thought it was time to give a little something back…
So I created a dashboard package from Umbraco 7 (using AngularJS and WebAPI) that allows an editor to check all the links within an Umbraco site.
Features
- Able to check an entire site, or just a section or even a single page
- Completely asynchronous so can check multiple links simultaneously and provide real-time feedback
- Caches link status so only checks each unique link once (within a short period)
- Works for all types of links - external, internal, HTML, files, images and even CSS and JavaScript files
- Provides feedback on errors with help dialogue plus an overview of all status codes
- Quick edit facility allows you to easily edit the page that contains the broken link directly within Umbraco
- Advanced options allow you to set the timeout period, toggle between viewing all checked links and only links that have problems
- You can whitelist HTTP codes and only report on those
- You can also configure it to ignore ports (if you are behind a reverse proxy, for example)
Screenshot
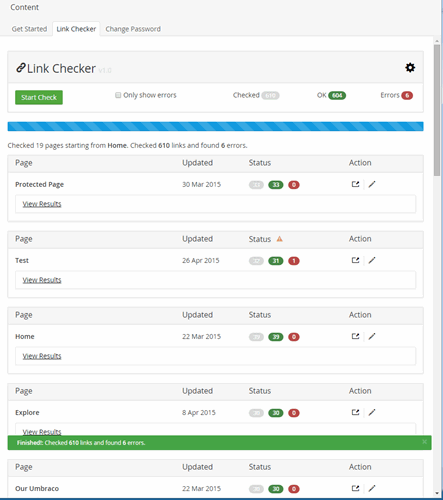
How it Works and Source Code
The basic premise is that the checker first iterates over every published page in the site from the chosen start node (using Umbraco's published content API) and creates a list of the page IDs to be checked.
This list is then passed back to an Angular controller that sends an asynchronous request to an Umbraco Web API controller, passing in the ID of the node to be checked.
A service then makes a HTTP GET request to the full URL of the page to get back the entire HTML for the page. This HTML is then parsed, using the HtmlAgility pack (which comes with Umbraco) and a list of every link in the page is collated. Certain link types are discarded that cannot be checked (such as mailto: links etc).
Another service then makes asynchronous HTTP HEAD requests to each of the links in the page using the HttpClient class in .NET that allows you to easily to make multiple requests in parallel (an HTTP HEAD request doesn't send back the content body, just the status, so is much faster than downloading entire pages). The HTTP status code of each request is then recorded and then sent back to the Angular controller that updates the UI with the results. I also keep a track of every URL that has been checked in a (in-memory) cache, and if the same URL is requested then the result is retrieved from memory, rather than re-checking it again.
The Angular UI layer then allows filtering to be performed as well as showing more detailed results for each link, including things like a full description of the status code, then line number in the HTML where the link was found etc.
Source Code
You can find the entire source code on my GitHub page. It's a bit rough, but hey, that's what pull requests are for!
NuGet
You can also install the package via NuGet:
Install-Package Diplo.LinkChecker
https://www.nuget.org/packages/Diplo.LinkChecker/
20 Comments
Tommy Enger
Hi! This looks great. Does it work with 7.3? I installed it, click on "Start check", select the root page. Then the "start check" button changes to "checking" and the text below says: "Checked 0 pages starting from Startpage". Nothing more happens, and it stays at "checked 0 pages..." No errors in the console.
Tommy Enger
Ok, I found a way to solve it quick and dirty. Changed to: $http.get(getIdsToCheckUrl + data.id).success(function (data, status, headers, config) { data = data.$values; ..............
Dan Diplo
Hi Tommy,
Strange, as I have tried installing Link Checker on Umbraco 7.3.0 and it worked OK... Was there something specific to your installation that was preventing it from working, do you think? Thanks for posting the fix - I'll bear it in mind for future releases.
Angelbert David
Hi there Dan,
I am trying to use your diplo link checker on Umbraco 6.2.5 (using your 1.5 version), but all the pages that are scanned return 0 links, even though I know that there are links on the pages.
I've tried a few things: -Links generated by the template -Links actually embeded in through the rich text editor on a page
Am I missing something? Some sort of configuration maybe?
thanks.
Dan Diplo
Hi Angelbert,
I'm afraid I don't really have the source for the older version, so it's hard to support it. It did use to work "out-of-the-box", but I haven't tried it on the later 6.2.x builds, I'm afraid.
Evan Moore
Thanks Dan, this is a great tool. I'm excited to look through your code and learn a few things about parsing HTML. I'm using Umbraco 7.3.4 and all external links on our website report as 403 or 404. I've not determined if this is an environmental issue or a problem with the link checker. Have you run into this?
Dan Diplo
Hi Evan,
A 403 normally means the URL exists but the application trying to access it doesn't have permission. Are any of these URLs password protected or require authentication?
One thing my Link Checker does is use HEAD requests rather than traditional GET request, since this is faster. Occasionally some servers will request this as they are configured to only accept GET/POST requests. That's my only thought.
Eric Schrepel
Trying to use this on Umbraco 7.1.4 and we happen to run the Umbraco BackOffice as https:// rather than http://. We're finding that all the pages return a ton of "bad" links that actually work fine but maybe the https:// is throwing the Diplo link checker? Didn't know if there was a way around this. Also, is it only checking links to pages within our site, or is it examining links to external sites also? We mostly care that our own pages aren't causing 404s, somewhat less so about outside links.
Dan Diplo
Eric, I can't think of any reason why it wouldn't work running under HTTPS links, but haven't actually tried it. I'll see if I can test it sometime. It is designed to check both internal and external links. Could you have some firewall or network policy that might be restricting outgoing traffic, perhaps?
blackhawk
This package works perfectly for me in Umbraco 7.6.6. Well done!
Jeremy Schlosser
Running Umbraco 7.5.8 with a reverse proxy. When checking URLs, it always inserts the port number after the domain. Is there a setting to not append the port number, or would this be an enhancement in future versions, or is this something that is entirely in Umbraco's purview.
Dan Diplo
Hi Jeremy,
Are you talking about when it checks the Umbraco pages or are you talking about when it checks the links within the pages?
When it checks an Umbraco page it determines the domain from the HttpContext.Request.Url - this is what ASP.NET returns as the URL of the page. I don't explicitly add a port - .NET would normally only add a port if the site was running on a non-standard port (ie. not 80 or 443).
When it checks links in the page it should just use the exact URL that is embedded within the page.
Unfortunately there is no way to manually configure this - it's not an issue I've ever seen mentioned before. I can only assume the reverse proxy somehow influences this.
Ben Sapp
Hi Dan, I work with Jeremy here. We're talking about when it checks links within the pages. Using non-standard ports with reverse proxies happens when the target of a reverse proxy hosts a bunch of different websites, which is what we have. Umbraco might be on port 12345 but this fact is concealed by the proxy, which only listens on 80 and 443. Like you say, the .Net URI will only include the port if it is non-standard, so we are looking for a setting that would cause baseUri in your HtmlParsingService omit the port number, where an href like "/a/page" turns into a request for "http://a.com/a/page" instead of "http://a.com:12345/a/page". Would you mind if we made a pull request for something like this? I would implement it in a similar way to the equivalent setting in the UrlTracker package: https://github.com/kipusoep/UrlTracker/pull/35 Thanks, Ben
Dan Diplo
Hi Ben,
I see. Yep, you are most welcome to make a pull request. I must admit I haven't performed any active development on it for a while, but am always most open to enhancements.
There is a very basic config file that exists, but this is in JavaScript, so may not be suitable (you'd have to pass any config value from it into the main C# services):
https://github.com/DanDiplo/Diplo.LinkChecker/blob/master/Diplo.LinkChecker/App_Plugins/Diplo.LinkChecker/config.js
Let me know how you get on!
Ben Sapp
Hi Dan, I just finished the pull request for your review. I did make a mistake in one of the xml comments which I noticed after finishing the pull request. The changes were so minor I didn't build or test it. Still, though (famous last words) I am confident the changes are good. I don't know the umbraco plugin packaging/publishing process... I will leave that to you, but let me know if you want me to take a stab at it. Thanks, Ben
Dan Diplo
Cheers, Ben, I'll review the commits today and then if all OK I'll merge and release a new package. Thanks for your input!
Ben
Hi Dan, I've just installed Diplo Link Checker on a clean install of Umbraco 7.12.2 and when I select any page to check I get: 500. An error has occurred. An error occurred while sending the request. Does the checker require any addition permissions in IIS? Any other ideas on what could be causing this? thanks for any help you can provide.
Dan Diplo
Hi Ben,
I've not tested it on 7.12.2 but there's no reason I can think of why it wouldn't work in that version - I'll check when I get a chance. It doesn't need any permissions, so long as the URL being checked is publicly accessible (if you use proxies or VPNs then it could cause issues).
Are you able to look in the Umbraco logs to see if there are any related errors logged there? Also, if you check the browser dev console (eg. F12 in Chrome) it may tell you more info. If you can definitely replicate an issue then log it at https://github.com/DanDiplo/Diplo.LinkChecker/issues
Alan
Hi Dan, I'm running Umbraco version 7.13.2 and I've installed Diplo link checker. When I do a check every link on the page comes up with an error .e.g. graphics etc which aren't broken etc. This seems to be because the Umbraco admin url is in the format https://editor.mydomain.co.uk/umbraco/ and not https://www.mydomain.co.uk/umbraco/ as the broken links are displaying as e.g. https://editor.mydomain.co.uk/images/logo.png. I there any way to fix this. Many thanks for you great plugin btw Alan
Dan Diplo
Hi Alan,
The checker determines the domain to use for checking content based on the current request. So if you are logged-in to a different domain to your site then, unfortunately, there is no simple way of determining your site is effectively hosted on a different domain.
An alternative to using my Link Checker would be to use the desktop app called Xenu Link Sleuth. Don't be put off by the basic website, it works well and is free to download. Hope that helps!
Leave a Comment
Just fill in the form and click Submit. But note all comments are moderated, so spare the viagra spam!
Tip: You can use Markdown syntax within comments.